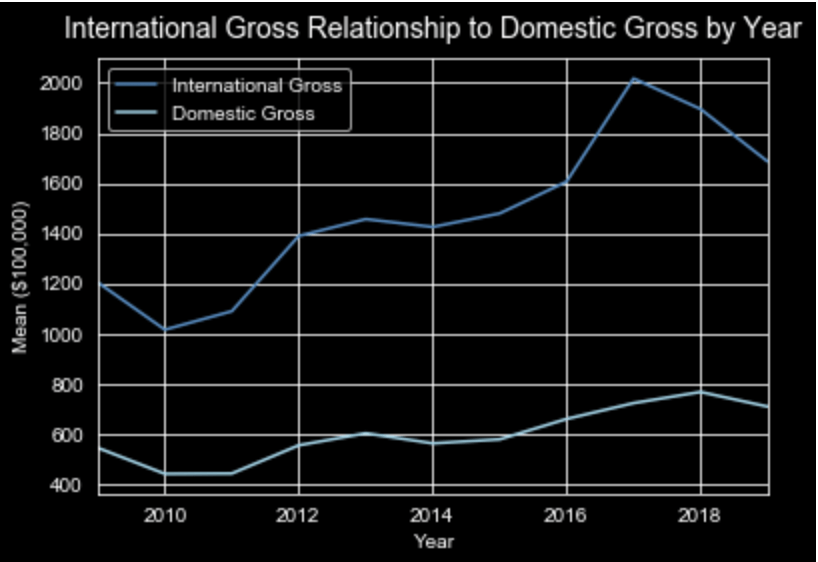
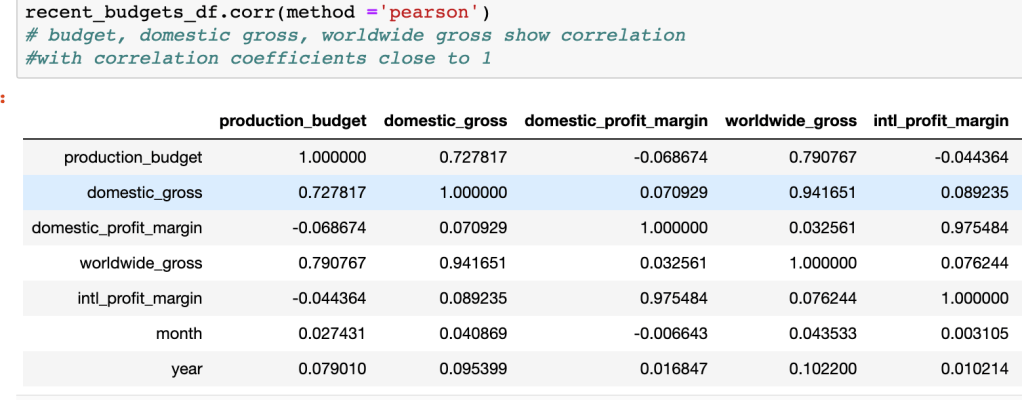
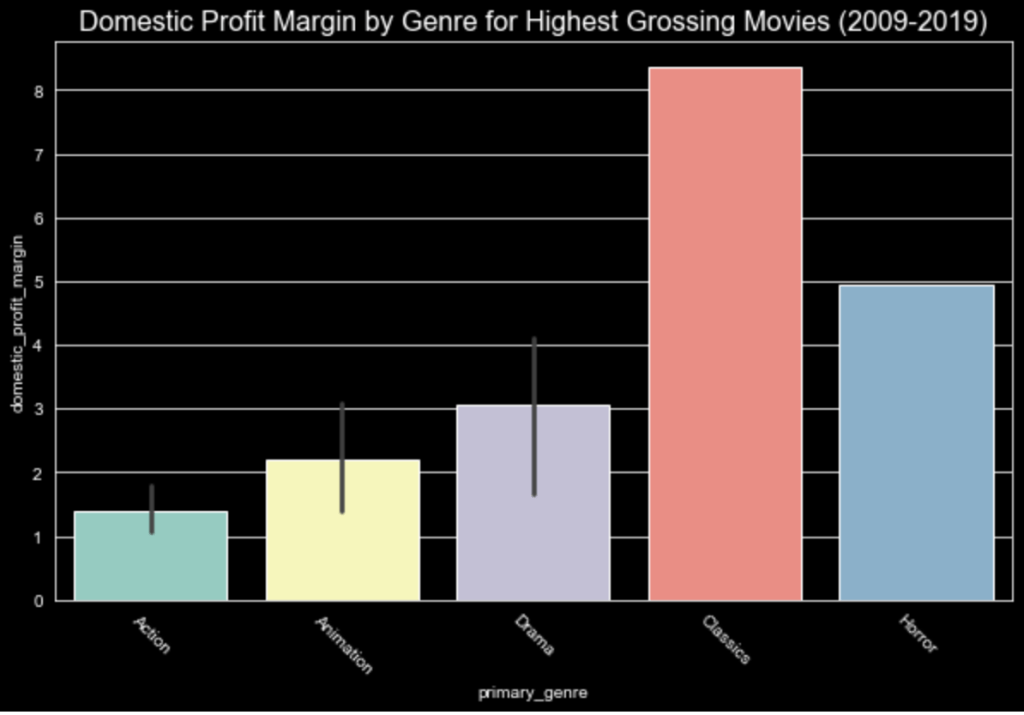
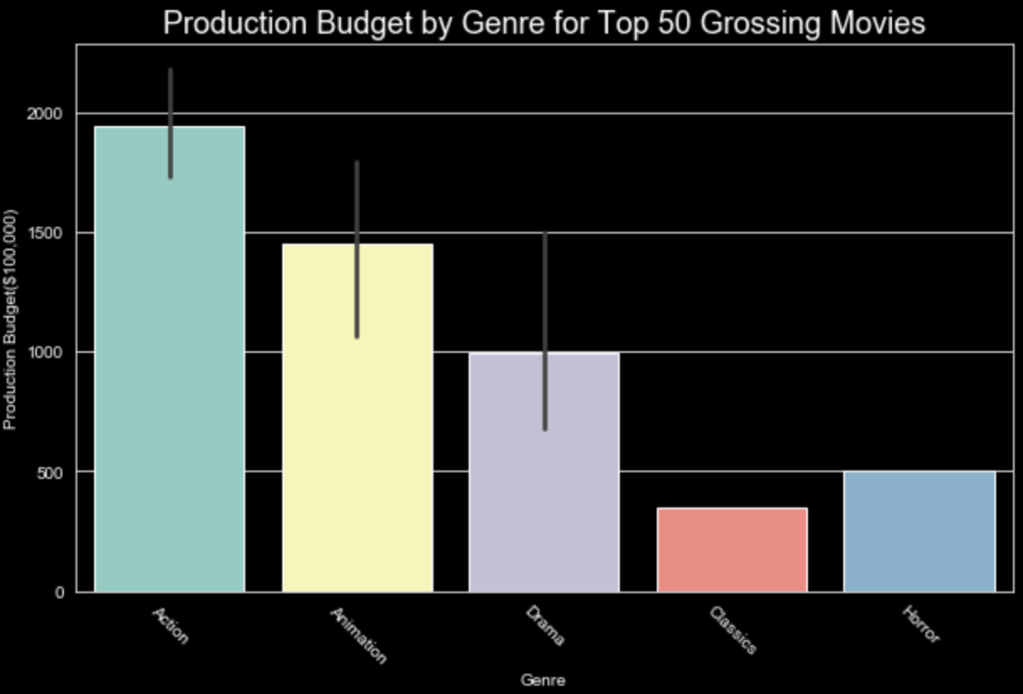
Using a dataset obtained through: https://data.world/crowdflower/brands-and-product-emotions, I processed the data obtained from Twitter. Preprocessing the tweets before creating a neural network I was able predict the sentiment using term frequency vectorization.
The dataset is unbalanced.
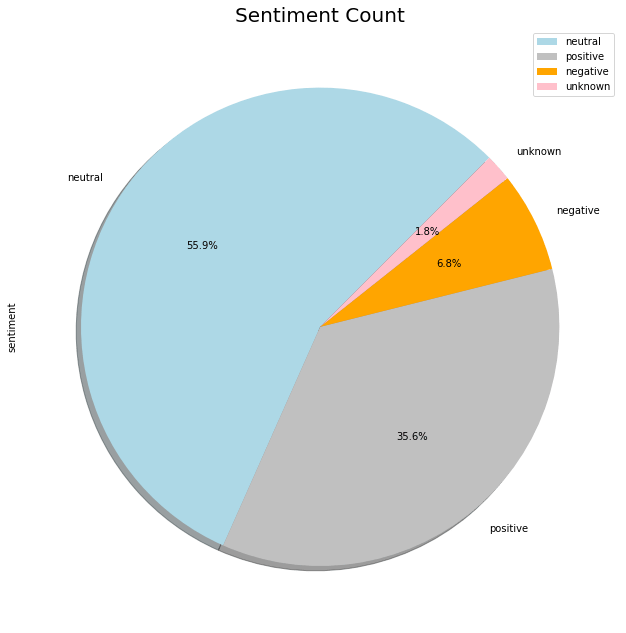
When I opt for binary classification using only positive and negative sentiment categorized tweets, my data looks more like this:
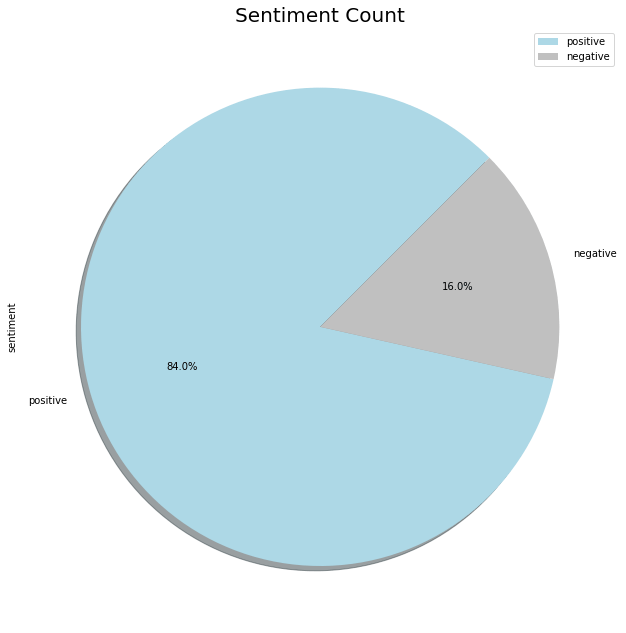
I will consider oversampling the negative data points a little later. First, to clean up the data before I utilize it.
I start by cleaning up the missing data. After cleaning up the NaN/missing data, I had tweets formatted like, well, your typical tweet as seen below.

I also renamed the columns to make my life a little easier.

Then, I applied the following functions to my dataset to get rid of the @mentions(Twitter user handles) and to decode the HTML, I used BeautifulSoup.

There were a lot of contractions present in the tweet text, so I used a dictionary to expand them into their compete words, most of which will be removed later through stopword removal. In order to get rid of the hashes preceding the hashtags, websites, auto-populated ‘{link} ‘ text, punctuation, string formatted numbers, possessive apostrophes and extraneous spaces, I applied the following function to return cleaned up text.

Next, I assessed the NLTK stopwords list and decided to add the brand and products to the stopwords and to remove ‘not’ from the list in the case that later, when I apply the n-grams parameter to my process, ‘not’ combined with the surrounding terms could help my network perform better. I also removed ‘sxsw’, and ‘austin’ because the dataset relates to the SXSW event in Austin, Texas. I didn’t want this to affect my assessment of the terms related to sentiment.
I used the NLTK TreebankWordTokenizer and TreebankWordDetokenizer to quickly create columns with tokens as well as an identical column that just contained the terms in a non-tokenized form for later use in Keras, eliminating the need for multiple list comprehension calls in my code. Additionally, after comparing the SnowballStemmer and the WordLemmatizer, I opted to use the lemmatized tokens, as when I applied the Part-Of-Speech tagging, the lemmatized terms allowed for more accurate tagging of verbs.

Next, I wanted to get a good visualization on the most common words in both the negative and positive sentiment categories.

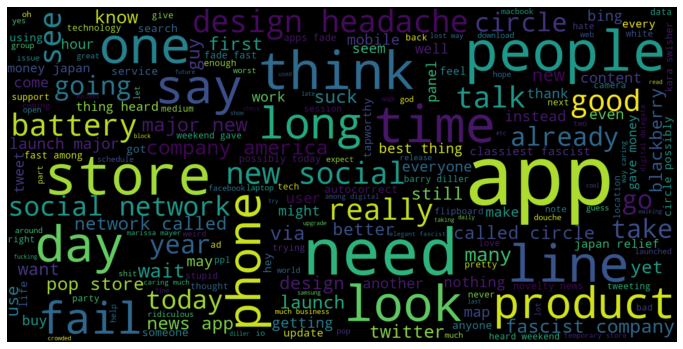


I processed my entire dataset, including the neutral and unknown sentiment categorized tweets. Next, I create a new Pandas dataframe that only contains the categories I plan to assess, which is positive and negative sentiment categorized tweets.

Now, I begin my model process by splitting my data into train, test, and validation sets. Then, I fit the TfidfVectorizer to my training data, and transform all of the data according to the fit to the training data. Then, I get the class weights for the sentiment classes to plug into my compile step.


Now, I compose my model.

I use the class weights when I fit the model to the training data.

My results aren’t bad considering the balance of data, and the overlapping that occurs within the classes.
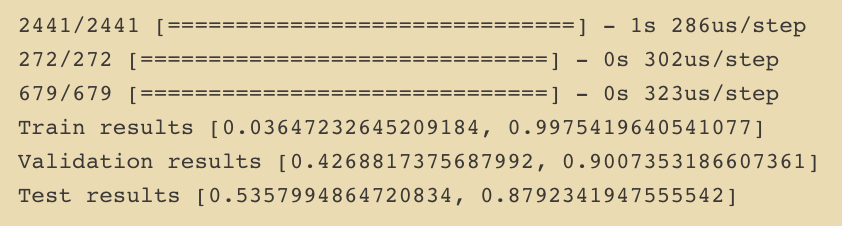

My next step is to obtain more data so that I can assess how the model performs on a larger and more varied dataset. Further assessment to be done on the means and word embeddings as well.