
Let me begin by saying, yes, the above spelling error is intentional, I know that ‘wrods’ is not how you spell ‘words’. The point of this is that it is very easy to mistype or incorrectly spell words when entering data, or when the data itself is subject to misspellings through user error. This is especially true in cases where you are analyzing data where each sample is input by a different user, such as data obtained from sites like Reddit or Twitter. This is almost always the case when hashtags are used inside text.
Previously, I discussed expanding hashtags when they are formatted using a mix of uppercase and lowercase characters, but frequently, there is no change in case to indicate word separation.
For example: #somepeopledothiscrap In similarly annoying fashion, other people will do this: #THEYDOTHISBECAUSETHEYAREANGRYORJUSTANNOYING
These cases require systematically iterating through each occurrence to find the best way to expand the characters to form words.
There is a package called SymSpell that works for the task of word segmentation for those pesky hashtags, or for individual words once your data is formatted in a way that makes it more efficient to check misspelled words.
Let’s start with the word segmentation module in SymSpell. Start by importing the following:
import pkg_resources from symspellpy import SymSpell
Next, I am creating a function with everything encompassed within the function to show how this works. I am setting the SymSpell argument ‘max_dictionary_edit_distance’ to 0, due to the fact that I am simply applying the word_segmentation function, so the only correction that needs to be made is adding spaces between the words to obtain the intended phrase.
I am using pkg.resources for the dictionary, which I assign to the variable ‘dictionary_path’. The dictionary is loaded, the term_index is the column of the dictionary term, and the count_index is the column for the term frequency.
Next, the return result variable is assigned, which contains the corrected_string, the distance_sum, and the log_prob_sum. In the function below, I am just concerned with getting the corrected_string, as a replacement for my mono cased hashtags.

Next, to correct the spelling of individual misspelled terms in your document, begin by importing the following:
import pkg_resources from symspellpy import SymSpell, Verbosity

Increasing the max_dictionary_edit_distance uses Levenshtein distance, which calculates the difference between two sequences by calculating the minimum count of single-character edits (insertions, deletions or substitutions between the original sequence and the new sequence. The Verbosity is set to ‘CLOSEST’ for the below results.
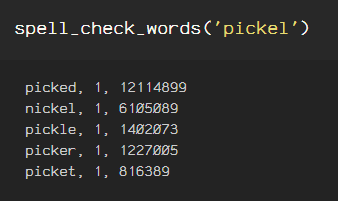
Another option for Verbosity is ‘TOP’, providing fewer options.


